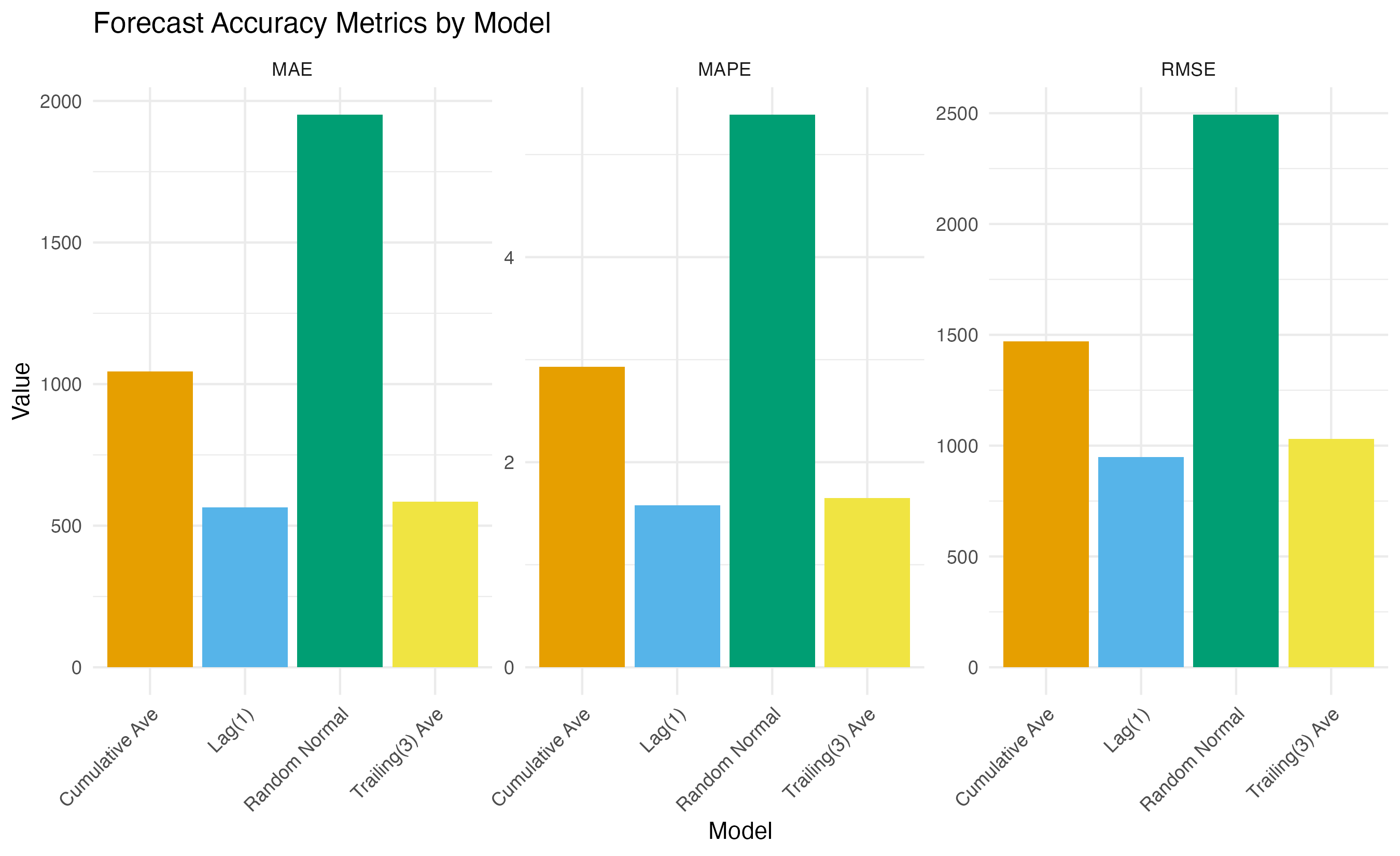
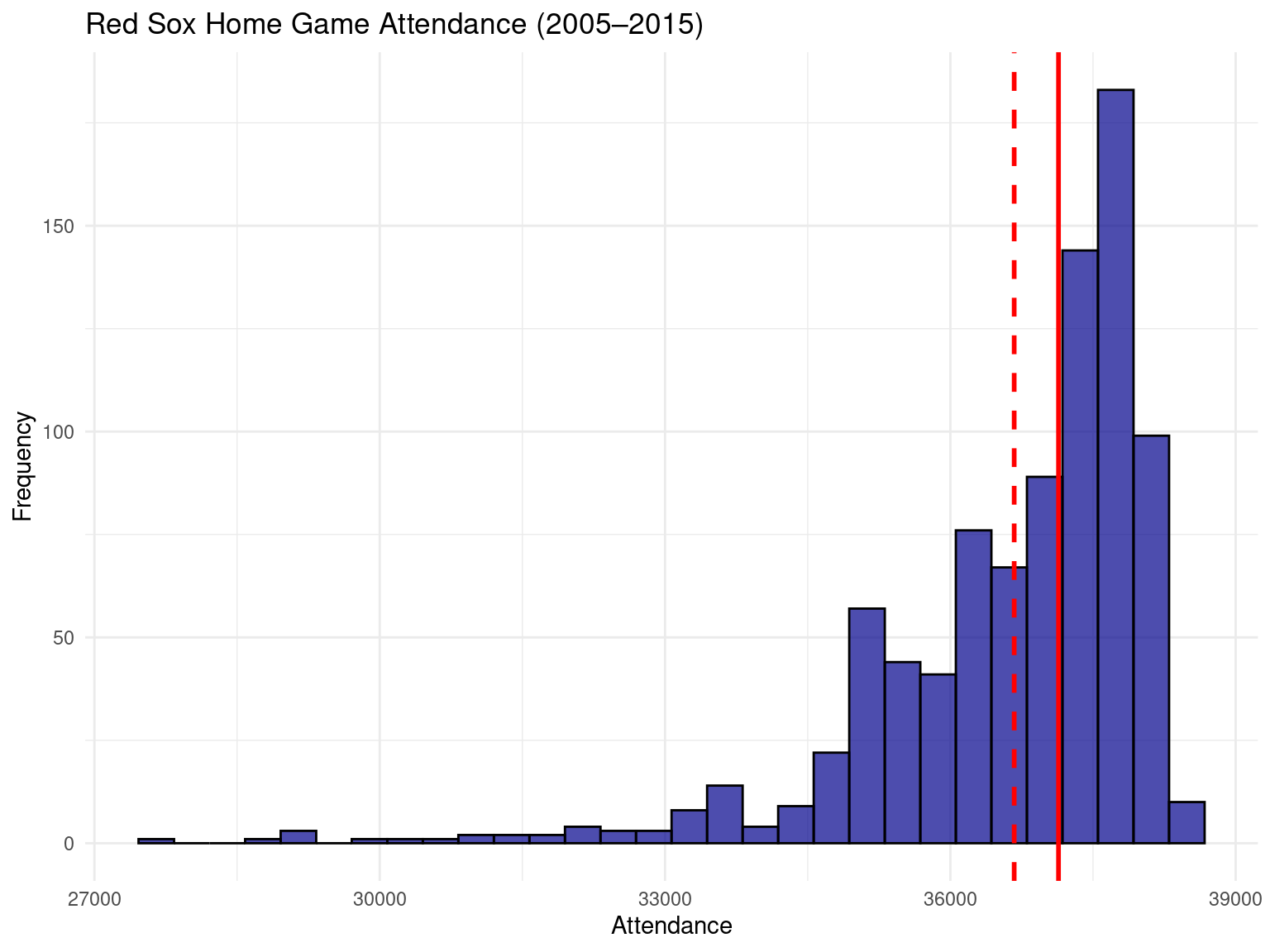
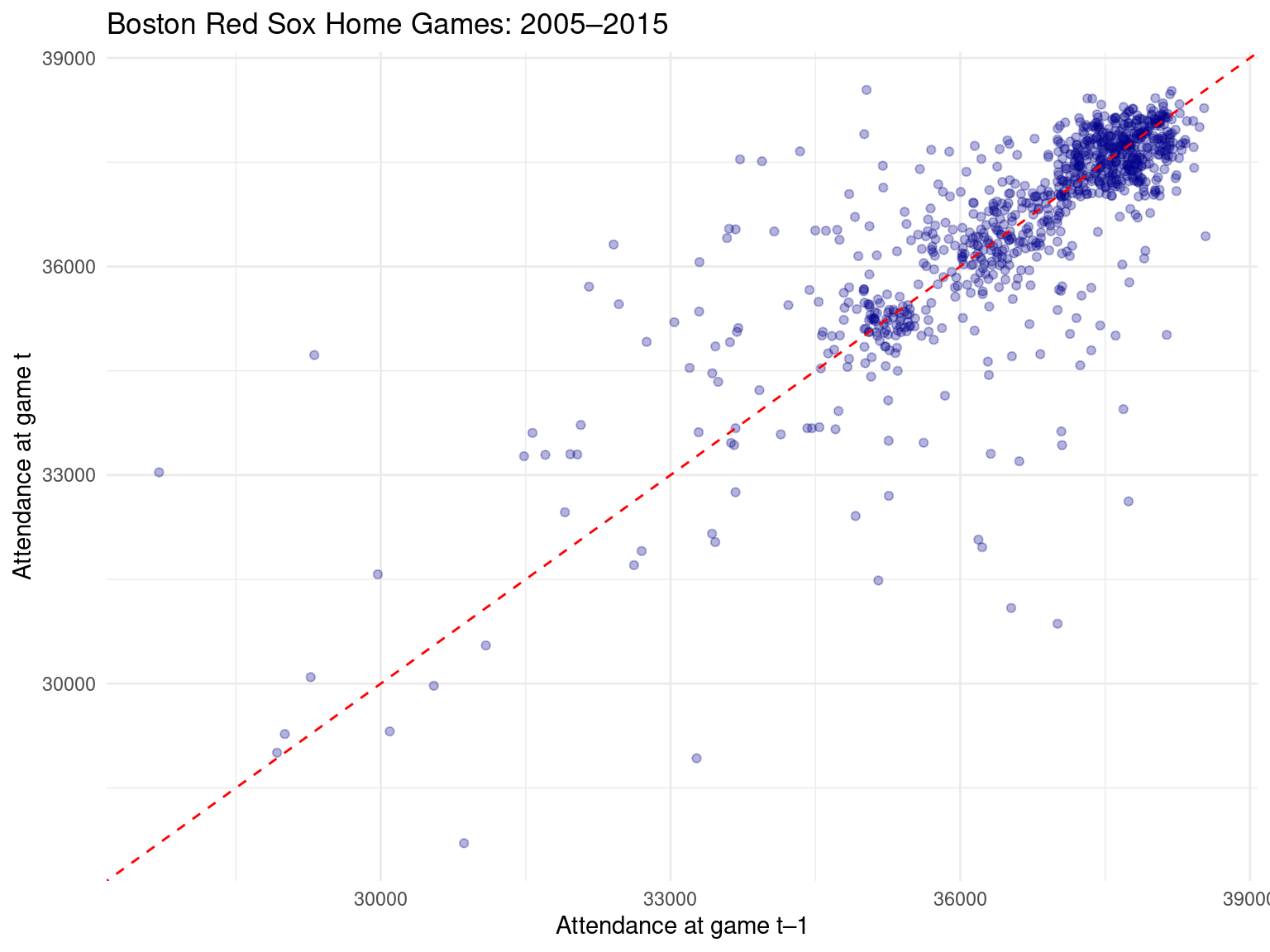
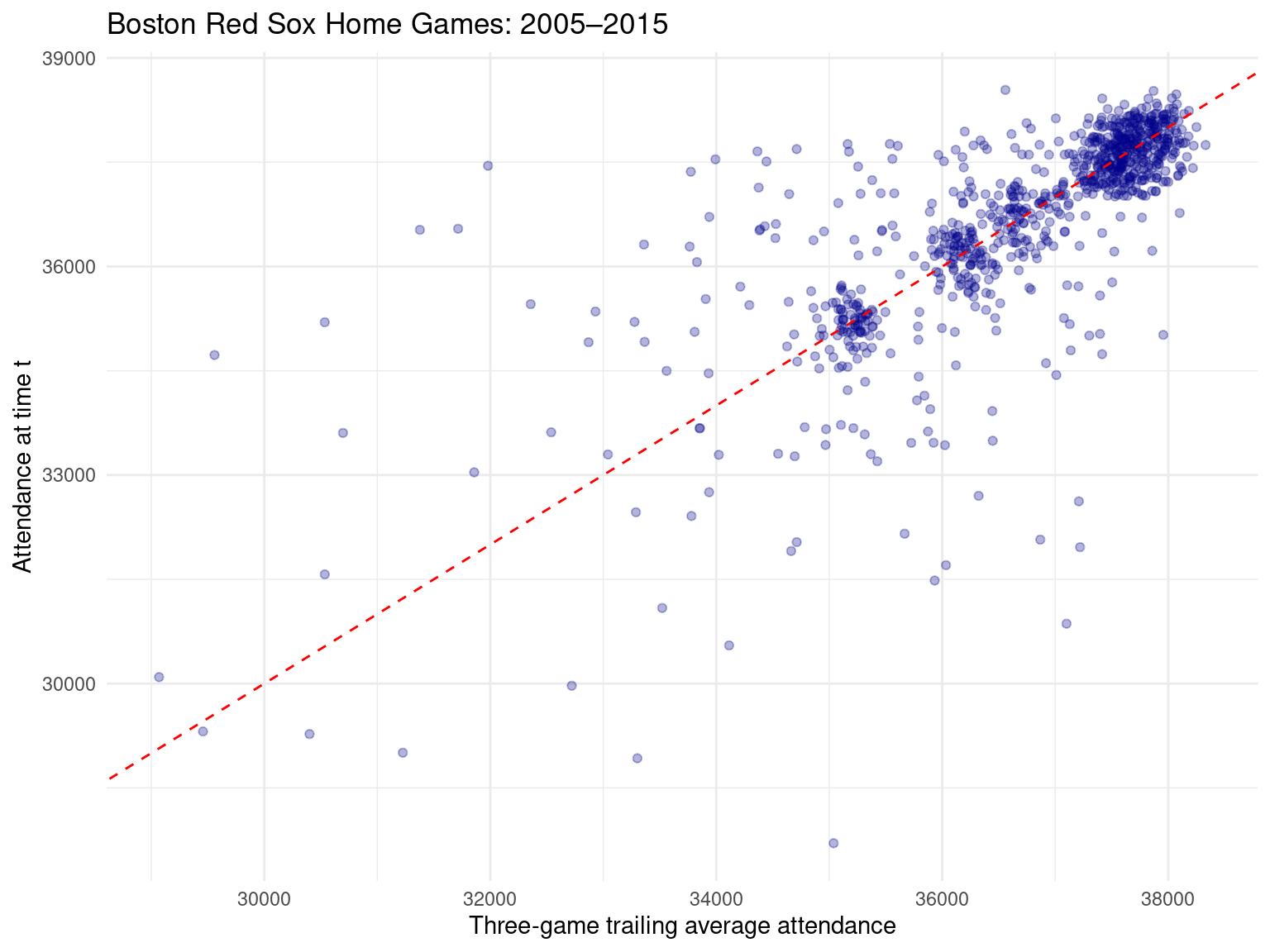
Rows: 162
Columns: 22
$ Gm <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, …
$ Date <chr> "Monday, Apr 6", "Wednesday, Apr 8", "Thursday, Apr 9",…
$ Tm <chr> "BOS", "BOS", "BOS", "BOS", "BOS", "BOS", "BOS", "BOS",…
$ H_A <chr> "A", "A", "A", "A", "A", "A", "H", "H", "H", "H", "H", …
$ Opp <chr> "PHI", "PHI", "PHI", "NYY", "NYY", "NYY", "WSN", "WSN",…
$ Result <chr> "W", "L", "W", "W", "W", "L", "W", "W", "L", "W-wo", "L…
$ R <dbl> 8, 2, 6, 6, 8, 4, 9, 8, 5, 3, 1, 3, 7, 1, 5, 1, 7, 4, 7…
$ RA <dbl> 0, 4, 2, 5, 4, 14, 4, 7, 10, 2, 4, 8, 1, 0, 7, 2, 5, 5,…
$ Inn <chr> "", "", "", "19", "", "", "", "", "", "", "", "", "7", …
$ Record <chr> "1-0", "1-1", "2-1", "3-1", "4-1", "4-2", "5-2", "6-2",…
$ Rank <dbl> 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 3…
$ GB <chr> "Tied", "0.5", "Tied", "Tied", "up 1.0", "Tied", "up 1.…
$ Win <chr> "Buchholz", "Harang", "Masterson", "Wright", "Kelly", "…
$ Loss <chr> "Hamels", "Porcello", "Buchanan", "Rogers", "Warren", "…
$ Save <chr> "", "Papelbon", "", "", "", "", "", "Uehara", "", "", "…
$ Time <chr> "3:01", "2:54", "3:08", "6:49", "3:13", "3:24", "3:01",…
$ `D/N` <chr> "D", "N", "N", "N", "D", "N", "D", "N", "D", "N", "D", …
$ Attendance <dbl> 45549, 26465, 23418, 41292, 46678, 43019, 37203, 35258,…
$ cLI <dbl> 0.92, 0.94, 0.89, 1.14, 1.13, 1.19, 1.01, 1.03, 1.07, 1…
$ Streak <dbl> 1, -1, 1, 2, 3, -1, 1, 2, -1, 1, -1, -2, 1, 2, -1, -2, …
$ Orig_Scheduled <chr> "", "", "", "", "", "", "", "", "", "", "", "", "", "",…
$ Year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2…